
数据仓库基本概念
一.数据仓库基本概念
1.1 数仓的概念
- 数据仓库(英语:Data Warehouse,简称数仓、DW),是一个用于存储、分析、报告的数据系统。
- 数据仓库的目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持(Decision Support)。
1.2 数仓专注分析
- 数据仓库本身并不“生产”任何数据,其数据来源于不同外部系统;
- 同时数据仓库自身也不需要“消费”任何的数据,其结果开放给各个外部应用使用;
- 这也是为什么叫“仓库”,而不叫“工厂”的原因。
- 联机事务处理系统(OLTP)正好可以满足上述业务需求开展, 其主要任务是执行联机事务处理。其基本特征是前台 接收的用户数据可以立即传送到后台进行处理,并在很短的时间内给出处理结果。
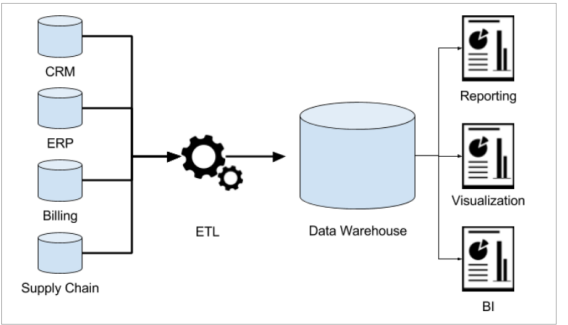
- 关系型数据库(RDBMS)是OLTP典型应用,比如:Oracle、MySQL、SQL Server等。
OLTP环境开展分析可行吗?
可以,但是没必要
OLTP系统的核心是面向业务,支持业务,支持事务。所有的业务操作可以分为读、写两种操作,一般来说读的压 力明显大于写的压力。如果在OLTP环境直接开展各种分析,有以下问题需要考虑:
数据分析也是对数据进行读取操作,会让读取压力倍增;
OLTP仅存储数周或数月的数据;
数据分散在不同系统不同表中,字段类型属性不统一;
1.3 数据仓库面世
- 当分析所涉及数据规模较小的时候,在业务低峰期时可以在OLTP系统上开展直接分析。
- 但为了更好的进行各种规模的数据分析,同时也不影响OLTP系统运行,此时需要构建一个集成统一的数据分析平 台。该平台的目的很简单:面向分析,支持分析,并且和OLTP系统解耦合。
- 基于这种需求,数据仓库的雏形开始在企业中出现了。
1.4 数据仓库的构建
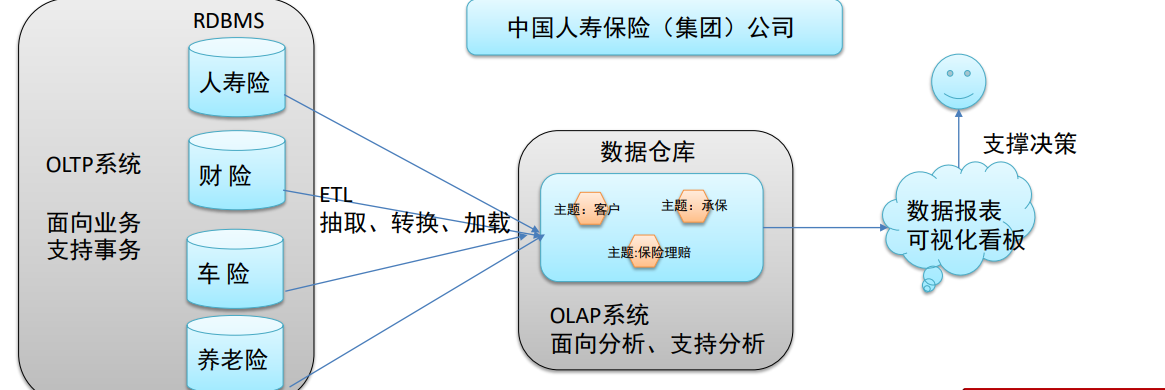
- 如数仓定义所说,数仓是一个用于存储、分析、报告的数据系统,目的是构建面向分析的集成化数据环境。我们把 这种面向分析、支持分析的系统称之为OLAP(联机分析处理)系统。当然,数据仓库是OLAP系统的一种实现。
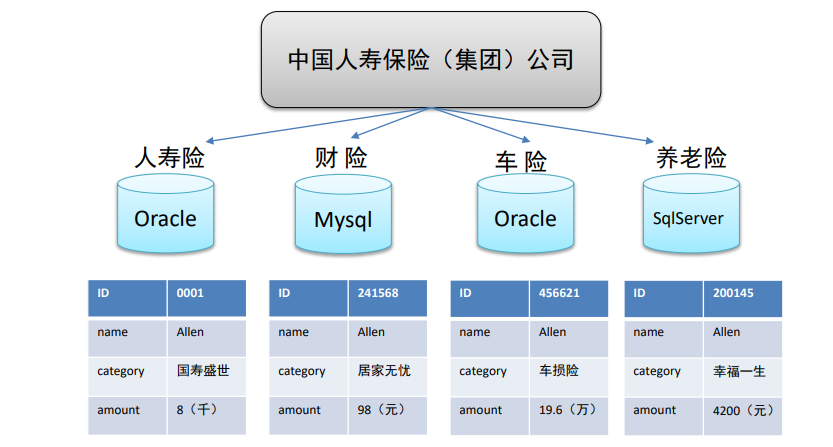
- 中国人寿保险公司就可以基于分析决策需求,构建数仓平台。
1.5数据仓库的主要特征
- 面向 主题
(Subject-Oriented)主题是一个抽象的概念,是较高层次上 数据综合、归类并进行分析利用的抽象
- 集成 性
(Integrated)主题相关的数据通常会分布在多个操作型 系统中,彼此分散、独立、异构。需要集 成到数仓主题下。
- 非易 失性
(Non-Volatile)也叫非易变性。数据仓库是分析数 据的平台,而不是创造数据的平台。
- 时变 性
(Time-Variant)数据仓库的数据需要随着时间更新,以适 应决策的需要。
1. 5.1 面向主题性(Subject-Oriented)
- 主题是一个抽象的概念,是较高层次上企业信息系统中的数据综合、归类并进行分析利用的抽象。在逻辑意义上, 它是对应企业中某一宏观分析领域所涉及的分析对象。
- 传统OLTP系统对数据的划分并不适用于决策分析。而基于主题组织的数据则不同,它们被划分为各自独立的领域 ,每个领域有各自的逻辑内涵但互不交叉,在抽象层次上对数据进行完整、一致和准确的描述。
1.5.2 集成性(Integrated)
- 主题相关的数据通常会分布在多个操作型系统中,彼此分散、独立、异构。
- 因此在数据进入数据仓库之前,必然要经过统一与综合,对数据进行抽取、清理、转换和汇总,这一步是数据仓库 建设中最关键、最复杂的一步,所要完成的工作有:
- 要统一源数据中所有矛盾之处; 如字段的同名异义、异名同义、单位不统一、字长不一致等等。
- 进行数据综合和计算。 数据仓库中的数据综合工作可以在从原有数据库抽取数据时生成,但许多是在数据仓库内部生成的,即进入数据仓库以 后进行综合生成的。
1.5.3 非易失性、非异变性(Non-Volatile)
- 数据仓库是分析数据的平台,而不是创造数据的平台。我们是通过数仓去分析数据中的规律,而不是去创造修改其 中的规律。因此数据进入数据仓库后,它便稳定且不会改变。
- 数据仓库的数据反映的是一段相当长的时间内历史数据的内容,数据仓库的用户对数据的操作大多是数据查询或比 较复杂的挖掘,一旦数据进入数据仓库以后,一般情况下被较长时间保留。
- 数据仓库中一般有大量的查询操作,但修改和删除操作很少。
1.5.4 时变性(Time-Variant)
- 数据仓库包含各种粒度的历史数据,数据可能与某个特定日期、星期、月份、季度或者年份有关。
- 当业务变化后会失去时效性。因此数据仓库的数据需要随着时间更新,以适应决策的需要。
- 从这个角度讲,数据仓库建设是一个项目,更是一个过程 。
二.数仓开发语言概述
1.1 数据仓库开发语言概述
- 数仓作为面向分析的数据平台,其主职工作就是对存储在其中的数据开展分析,那么如何读取数据分析呢?
- 理论上来说,任何一款编程语言只要具备读写数据、处理数据的能力,都可以用于数仓的开发。比如大家耳熟能详 的C、java、Python等;
- 关键在于编程语言是否易学、好用、功能是否强大。遗憾的是上面所列出的C、Python等编程语言都需要一定的时 间进行语法的学习,并且学习语法之后还需要结合分析的业务场景进行编码,跑通业务逻辑。
- 不管从学习成本还是开发效率来说,上述所说的编程语言都不是十分友好的。
- 在数据分析领域,不得不提的就是SQL编程语言,应该称之为分析领域主流开发语言。
1.2 SQL语言介绍
- 结构化查询语言(Structured Query Language)简称SQL,是一种数据库查询和程序设计语言,用于存取数据 以及查询、更新和管理数据。
- SQL语言使我们有能力访问数据库,并且SQL是一种ANSI(美国国家标准化组织)的标准计算机语言,各大数据库 厂商在生产数据库软件的时候,几乎都会去支持SQL的语法,以使得用户在使用软件时更加容易上手,以及在不同 厂商软件之间进行切换时更加适应,因为大家的SQL语法都差不多。
- SQL语言功能很强,十分简洁,核心功能只用了9个动词。语法接近英语口语,所以,用户很容易学习和使用。
1.3 数据仓库与SQL
- 虽然SQL语言本身是针对数据库软件设计的,但是在数据仓库领域,尤其是大数据数仓领域,很多数仓软件都会去 支持SQL语法;
- 原因在于一是用户学习SQL成本低,二是SQL语言对于数据分析真的十分友好,爱不释手。
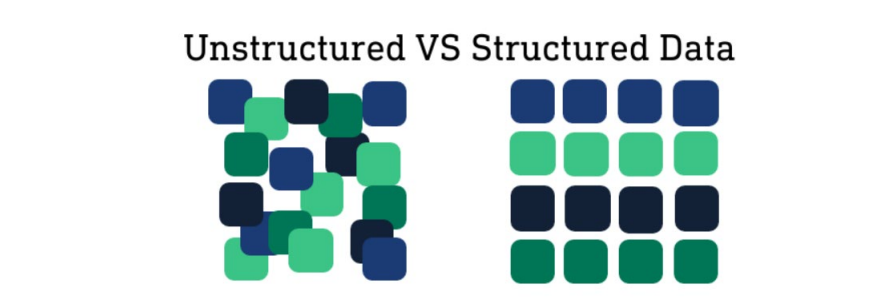
1.4 结构化数据
- 结构化数据也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格地遵循数据格式与长度规范,主要通过 关系型数据库进行存储和管理。
- 与结构化数据相对的是不适于由数据库二维表来表现的非结构化数据,包括所有格式的办公文档、XML、HTML、 各类报表、图片和音频、视频信息等。
- 通俗来说,结构化数据会有严格的行列对齐,便于解读与理解。
1.5 二维表结构
- 表由一个名字标识(例如“客户”或者“订单”),叫做表名。表包含带有数据的记录(行)。
- 下面的例子是一个名为 “Persons” 的表,包含三条记录(每一条对应一个人)和五个列(Id、姓、名、地址和 城市)。

1.6 SQL语法分类
SQL主要语法分为两个部分:数据定义语言 (DDL)和数据操纵语言 (DML) 。
DDL语法使我们有能力创建或删除表,以及数据库、索引等各种对象,但是不涉及表中具体数据操作:
CREATE DATABASE - 创建新数据库
CREATE TABLE - 创建新表
DML语法是我们有能力针对表中的数据进行插入、更新、删除、查询操作:
SELECT - 从数据库表中获取数据
UPDATE - 更新数据库表中的数据
DELETE - 从数据库表中删除数据
INSERT - 向数据库表中插入数据
三 .Apache Hive 入门
1.1 什么是Hive
- Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化 数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hive查询语言(HQL),用于访问和 分析存储在Hadoop文件中的大型数据集。
- Hive核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop群集执行。
- Hive由Facebook实现并开源。

1.2 为什么使用Hive
使用Hadoop MapReduce直接处理数据所面临的问题
- 人员学习成本太高 需要掌握java语言
- MapReduce实现复杂查询逻辑开发难度太大
使用Hive处理数据的好处
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
- 避免直接写MapReduce,减少开发人员的学习成本 支持自定义函数,功能扩展很方便
- 背靠Hadoop,擅长存储分析海量数据集
1.3 Hive 和Hadoop关系
- 从功能来说,数据仓库软件,至少需要具备下述两种能力: 存储数据的能力、分析数据的能力
- Apache Hive作为一款大数据时代的数据仓库软件,当然也具备上述两种能力。只不过Hive并不是自己实现了上述 两种能力,而是借助Hadoop。
- Hive利用HDFS存储数据,利用MapReduce查询分析数据。
- 这样突然发现Hive没啥用,不过是套壳Hadoop罢了。其实不然,Hive的最大的魅力在于用户专注于编写HQL,
- Hive帮您转换成为MapReduce程序完成对数据的分析。
1.4 Hive架构
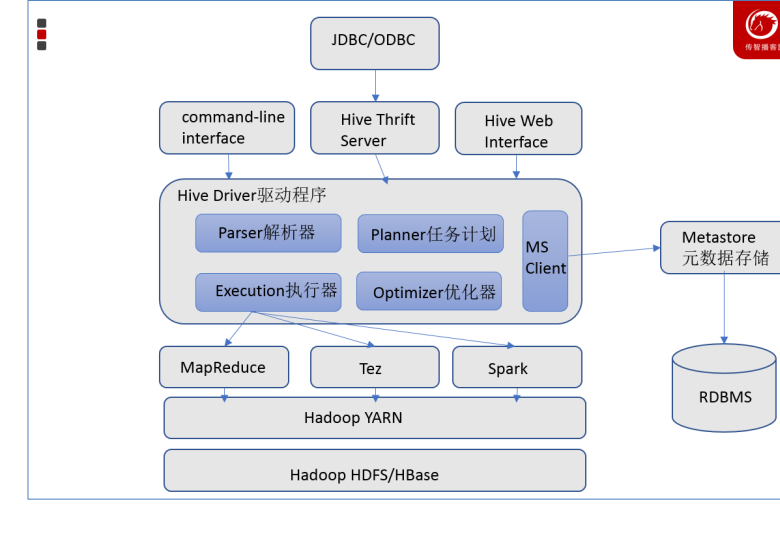
1.5 Hive组件
包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)为shell命令行;Hive中的Thrift服务器允许 外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。WebGUI是通过浏览器访问Hive。
通常是存储在关系数据库如 mysql/derby中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是 否为外部表等),表的数据所在目录等。
完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在 随后有执行引擎调用执行。
Hive本身并不直接处理数据文件。而是通过执行引擎处理。当下Hive支持MapReduce、Tez、Spark3种执行引擎。




