defstart_requests(self): cls = self.__class__ ifnot self.start_urls andhasattr(self, 'start_url'): raise AttributeError( "Crawling could not start: 'start_urls' not found " "or empty (but found 'start_url' attribute instead, " "did you miss an 's'?)") if method_is_overridden(cls, Spider, 'make_requests_from_url'): warnings.warn( "Spider.make_requests_from_url method is deprecated; it " "won't be called in future Scrapy releases. Please " "override Spider.start_requests method instead (see %s.%s)." % ( cls.__module__, cls.__name__ ), ) for url in self.start_urls: yield self.make_requests_from_url(url) else: for url in self.start_urls: # 核心就这么一句话. 组建一个Request对象.我们也可以这么干. yield Request(url, dont_filter=True)
defstart_requests(self): # 直接从浏览器复制 cookies = "GUID=bbb5f65a-2fa2-40a0-ac87-49840eae4ad1; c_channel=0; c_csc=web; Hm_lvt_9793f42b498361373512340937deb2a0=1627572532,1627711457,1627898858,1628144975; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F16%252F16%252F64%252F75836416.jpg-88x88%253Fv%253D1610625030000%26id%3D75836416%26nickname%3D%25E5%25AD%25A4%25E9%25AD%2582%25E9%2587%258E%25E9%25AC%25BCsb%26e%3D1643697376%26s%3D73f8877e452e744c; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2275836416%22%2C%22%24device_id%22%3A%2217700ba9c71257-035a42ce449776-326d7006-2073600-17700ba9c728de%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%2C%22first_id%22%3A%22bbb5f65a-2fa2-40a0-ac87-49840eae4ad1%22%7D; Hm_lpvt_9793f42b498361373512340937deb2a0=1628145672" cookie_dic = {} for c in cookies.split("; "): k, v = c.split("=") cookie_dic[k] = v
USER_AGENT_LIST = [ 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36', 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2919.83 Safari/537.36', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2866.71 Safari/537.36', 'Mozilla/5.0 (X11; Ubuntu; Linux i686 on x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2820.59 Safari/537.36', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2762.73 Safari/537.36', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2656.18 Safari/537.36', 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML like Gecko) Chrome/44.0.2403.155 Safari/537.36', 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.1 Safari/537.36', 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36', 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2226.0 Safari/537.36', 'Mozilla/5.0 (Windows NT 6.4; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2225.0 Safari/537.36', 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2225.0 Safari/537.36', 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2224.3 Safari/537.36', 'Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.93 Safari/537.36', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.124 Safari/537.36', 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36', 'Mozilla/5.0 (Windows NT 4.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36', ]
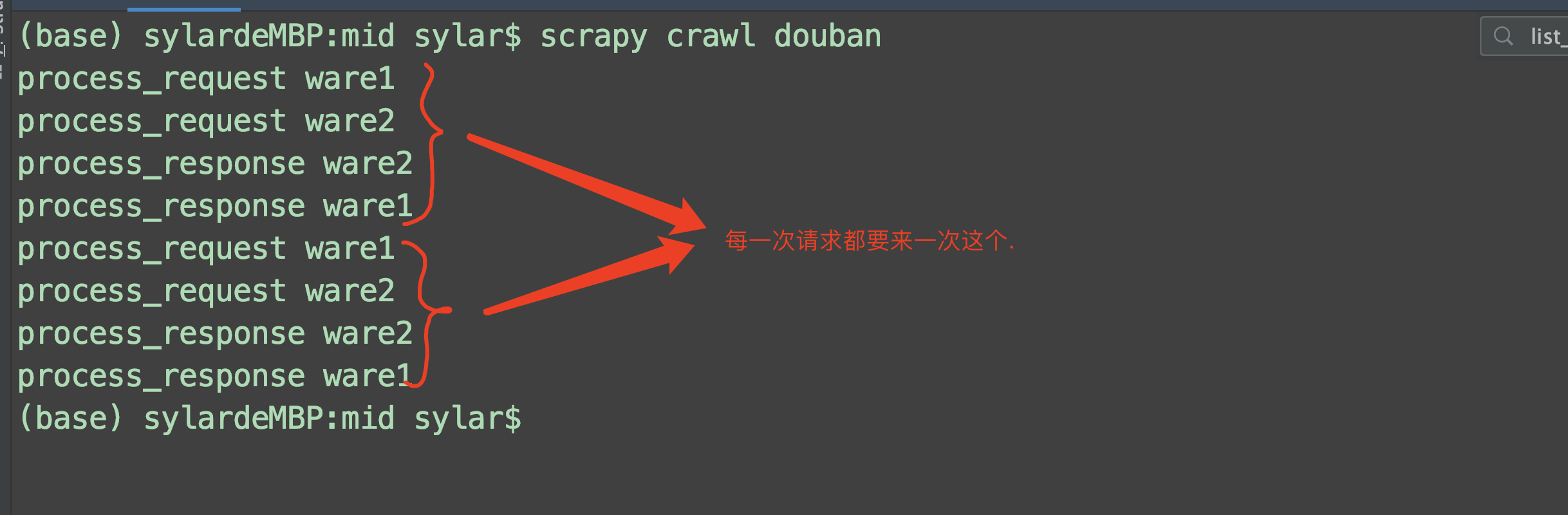
中间件
1 2 3 4 5 6 7 8 9 10 11 12
classMyRandomUserAgentMiddleware:
defprocess_request(self, request, spider): UA = choice(USER_AGENT_LIST) request.headers['User-Agent'] = UA # 不要返回任何东西
defparse(self, resp, **kwargs): li_list = resp.xpath('//*[@id="main"]/div/div[3]/ul/li') for li in li_list: href = li.xpath("./div[1]/div[1]/div[1]/div[1]/div[1]/span[1]/a[1]/@href").extract_first() name = li.xpath("./div[1]/div[1]/div[1]/div[1]/div[1]/span[1]/a[1]/text()").extract_first()
@classmethod deffrom_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() # 这里很关键哦. # 在爬虫开始的时候. 执行spider_opened # 在爬虫结束的时候. 执行spider_closed crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) crawler.signals.connect(s.spider_closed, signal=signals.spider_closed) return s
@classmethod deffrom_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) return s
web.find_element_by_xpath('/html/body/div[3]/div/div[3]/div[1]/form/p[4]/input').click() time.sleep(3) cookies = web.get_cookies() self.cookie = {dic['name']:dic['value'] for dic in cookies} web.close()
defbase64_api(self, uname, pwd, b64_img, typeid): data = { "username": uname, "password": pwd, "typeid": typeid, "image": b64_img } result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text) if result['success']: return result["data"]["result"] else: return result["message"]
classCuowuSpiderMiddleware: # Not all methods need to be defined. If a method is not defined, # scrapy acts as if the spider middleware does not modify the # passed objects.
@classmethod deffrom_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) return s
defprocess_spider_output(self, response, result, spider): # 处理完spider中的数据. 返回数据后. 执行 # 返回值要么是item, 要么是request. print("我是process_spider_output") for i in result: yield i print("我是process_spider_output")
# Must return only requests (not items). for r in start_requests: yield r
defspider_opened(self, spider): pass
items
1 2 3
classErrorItem(scrapy.Item): name = scrapy.Field() url = scrapy.Field()
spider:
1 2 3 4 5 6 7 8 9 10 11 12
classBaocuoSpider(scrapy.Spider): name = 'baocuo' allowed_domains = ['baidu.com'] start_urls = ['http://www.baidu.com/']
defparse(self, resp, **kwargs): name = resp.xpath('//title/text()').extract_first() # print(1/0) # 调整调整这个. 简单琢磨一下即可~~ it = CuowuItem() it['name'] = name print(name) yield it